

In today’s data-driven world, understanding how data is stored is paramount for success in any project or endeavor. From traditional relational databases to cutting-edge data lakehouses, there exists a plethora of data storage types, each tailored to specific needs and use cases. Let’s delve into the essential data storage types you need to know to navigate the complex landscape of data management effectively.
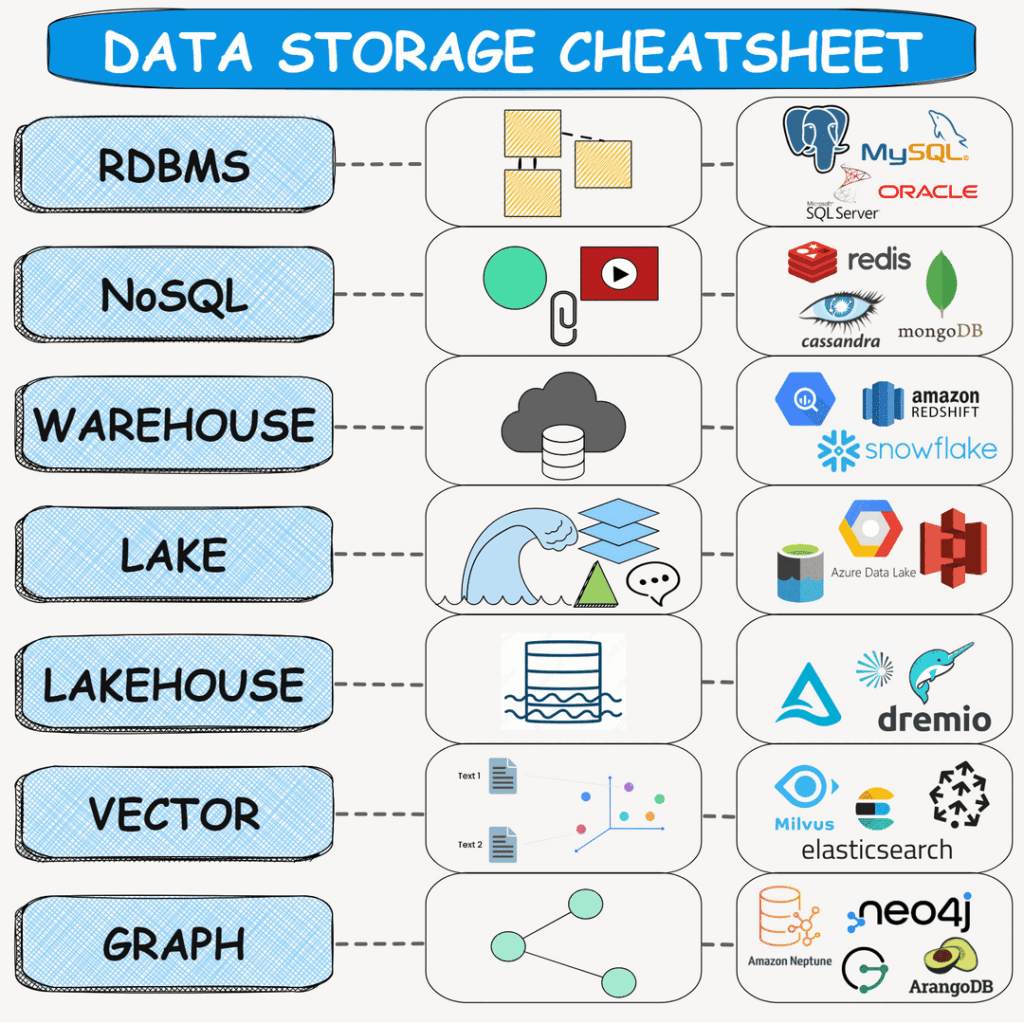
RDBMS Databases:
Relational Database Management Systems (RDBMS) are the stalwarts of structured data storage. They are designed with predefined schemas, ensuring data consistency and integrity. RDBMS databases provide ACID properties (Atomicity, Consistency, Isolation, Durability), making them ideal for applications requiring robust transactional support. Examples include Oracle MySQL, PostgreSQL, Microsoft SQL Server, among others.
NoSQL Databases:
NoSQL databases emerged to address the limitations of RDBMS in handling unstructured and semi-structured data. Offering flexibility, scalability, and high performance, NoSQL databases come in various types such as document, key-value, wide-column, and graph databases. Popular examples include MongoDB, Apache Cassandra, Redis, and Neo4j.
Data Warehouse:
Data Warehouses are optimized for querying and analyzing large volumes of data using a schema-on-write approach. They excel in supporting historical data analysis and reporting, often employing ETL (Extract, Transform, Load) processes to populate the warehouse. Prominent examples include Snowflake, Amazon Redshift, and Google BigQuery.
Data Lake:
A Data Lake serves as a centralized repository for raw, unstructured, and semi-structured data at scale. It offers cost-effective storage and processing of vast data volumes and supports a schema-on-read approach for flexible data analysis. Notable examples include Microsoft Azure Data Lake, Amazon S3, and Google Cloud Storage.
Data Lakehouse:
Combining the best of both Data Warehouse and Data Lake, a Data Lakehouse provides a unified platform for storing structured, semi-structured, and unstructured data. It supports ACID transactions, schema enforcement, and enables real-time analytics, business intelligence, and machine learning. Examples encompass Dremio, Delta Lake, and Starburst.
Vector Database:
Vector Databases are specialized in storing and querying high-dimensional vector data, often utilized in machine learning applications for similarity search and nearest neighbor queries. Examples in this domain include Milvus, Elastic, and Pinecone.
Graph Database:
Designed for storing and querying highly connected data with complex relationships, Graph Databases excel in representing data as nodes (entities) and edges (relationships). They are optimized for traversing and analyzing relationships between entities, finding applications in social networks, fraud detection, and knowledge graphs. Leading examples include Neo4j, Amazon Neptune, JanusGraph, and ArangoDB.
Conclusion
In conclusion, the landscape of data storage types is diverse and continually evolving to meet the demands of modern data-driven enterprises. Each type offers unique capabilities and advantages, catering to specific use cases and requirements. Whether you’re working with structured databases, exploring the depths of unstructured data lakes, or harnessing the power of graph databases for complex relationships, understanding these storage types is essential for driving innovation and success in your projects.
What data systems have you worked with in your projects? Share your experiences and insights in the comments below!