

Are you intrigued by the potential of Spark Structured Streaming in Databricks but unsure where to begin? Look no further. In this comprehensive guide, we’ll delve into the intricacies of Spark Structured Streaming, demystifying its concepts and showcasing its powerful capabilities.
Understanding Data Streams
Let’s start with the basics. What exactly is a data stream, and how does Spark Structured Streaming handle it? A data stream is any continuously growing data source, such as new log files landing in cloud storage, database updates captured through Change Data Capture (CDC), or events queued in messaging systems like Kafka.
Traditionally, processing data streams involved either reprocessing the entire dataset upon each update or implementing custom logic to capture only new additions. However, Spark Structured Streaming offers a more efficient solution by treating the data stream as an ever-expanding table of records.
Spark Structured Streaming: A Scalable Solution
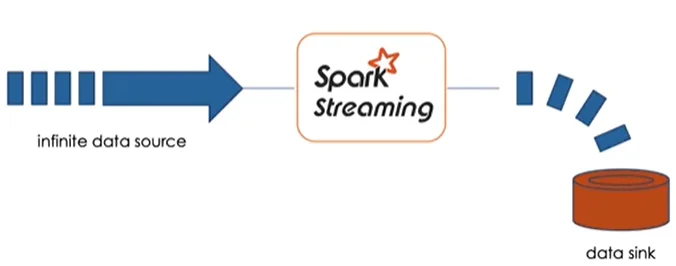
At the heart of Spark Structured Streaming lies a scalable streaming processing engine. It seamlessly integrates with various data sources, automatically detecting new data and incrementally persisting results into a data sink, such as files or tables.
The beauty of Spark Structured Streaming lies in its simplicity. By treating the infinite data source as a static table, users can interact with it using familiar SQL-like queries, with new data seamlessly appended as new rows to the table.
Integration with Delta Lake
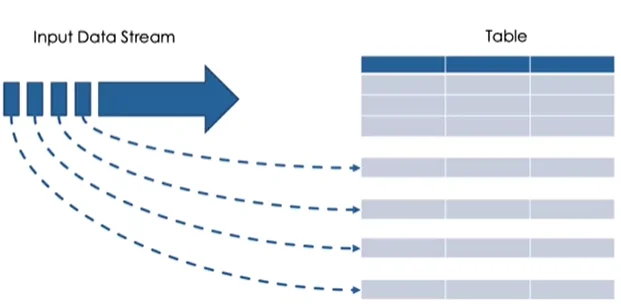
For those utilizing Delta Lake, Spark Structured Streaming offers seamless integration. You can effortlessly query Delta tables as stream sources, processing both existing data and incoming updates in real-time. This creates a streaming data frame on which transformations can be applied just like a static data frame.
Configuring Streaming Writes
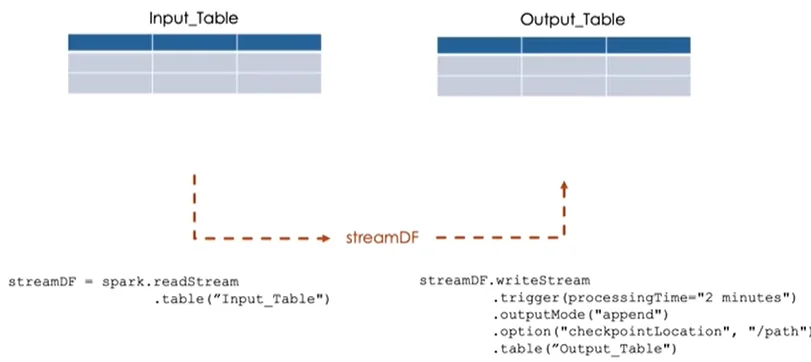
To persist the results of streaming queries, Spark Structured Streaming provides the writeStream method. This method allows you to configure various parameters, including the trigger interval, which determines how frequently the system processes new data. You can choose from options such as fixed intervals or batch modes to process available data at once.
Ensuring Fault Tolerance and Exactly-Once Semantics
Fault tolerance is paramount in streaming processing. Spark Structured Streaming achieves this through checkpoints & write-ahead logs, which track the progress of streaming jobs and allow for seamless recovery in case of failures. Additionally, the use of idempotent sinks ensures exactly-once data processing, preventing duplicate writes even under failure conditions.
Limitations and Advanced Techniques
While most operations on streaming data frames mirror those on static data frames, there are exceptions. Operations like sorting and deduplication may pose challenges in streaming contexts. However, advanced techniques such as windowing and watermarking can help overcome these limitations, enabling more complex analyses on streaming data.
Conclusion
In conclusion, Spark Structured Streaming in Databricks offers a robust solution for processing continuous streams of data. By seamlessly integrating with various data sources and providing fault-tolerant processing with exactly-once semantics, it empowers users to derive valuable insights from streaming data with ease.
Whether you’re a seasoned data engineer or a curious beginner, Spark Structured Streaming opens up a world of possibilities for real-time data processing. So why wait? Dive in and unlock the potential of streaming analytics with Spark Structured Streaming in Databricks.
Related Posts
What is ACID in Databases ?
Atomicity: Imagine you're transferring money between accounts. If the transfer…

Exploring the Essential Data Storage Types: A Guide for Success
In today's data-driven world, understanding how data is stored is…
What is Amazon Personalize?
From search results to your phone's news feed to social…